Abstract
We present the Stochastic Decoupled Policy Gradient (SDPG), a lightweight visual reinforcement learning (RL) method that trains diverse visuomotor control policies end-to-end within a few hours on a single NVIDIA RTX 4080 GPU. SDPG estimates policy gradients via random perturbations of trajectory rollouts, requiring orders of magnitude fewer batch-rendered environments and substantially reducing compute and memory overhead. On visual MuJoCo benchmarks, SDPG consistently outperforms baseline methods in training time, memory usage, and rewards. Finally, to support future research, we introduce a suite of realistic visual robotics benchmarks spanning dexterous manipulation and challenging locomotion, and demonstrate effective sim-to-real transfer on physical hardware.
Method Overview
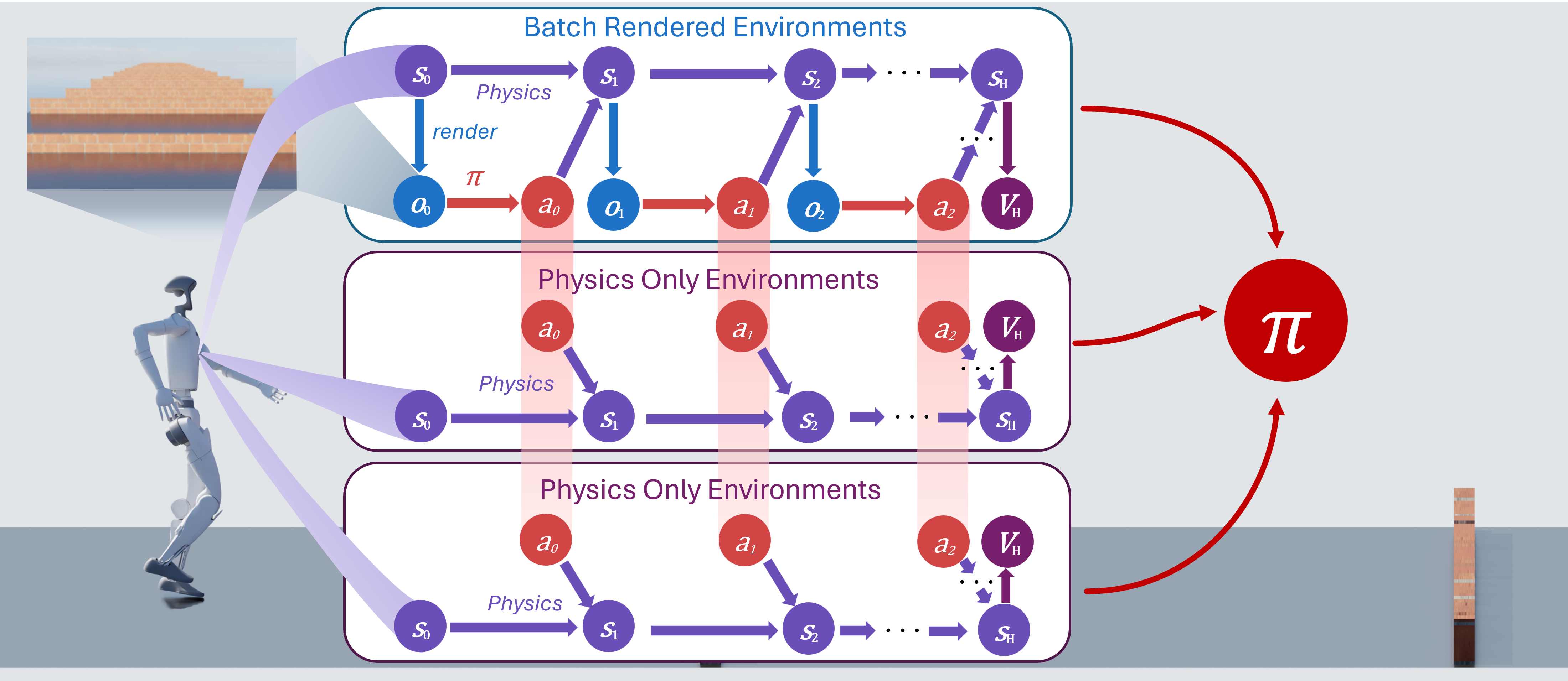
SDPG combines batch-rendered and physics-only environments to estimate policy gradients. Batch-rendered environments evaluate policy performance, while physics-only environments provide perturbed rollouts for policy improvement. This mixture of environments significantly reduces the computation and memory overhead. We also introduce several engineering improvements—such as an adaptive exploration strategy and reward-invariant normalization—to keep updates numerically stable throughout training.
Visual MuJoCo Benchmark
On visual MuJoCo benchmarks, SDPG achieves high rewards, matching state-based performance, and fast training, on par with distillation and far quicker than other end-to-end visual RL methods.
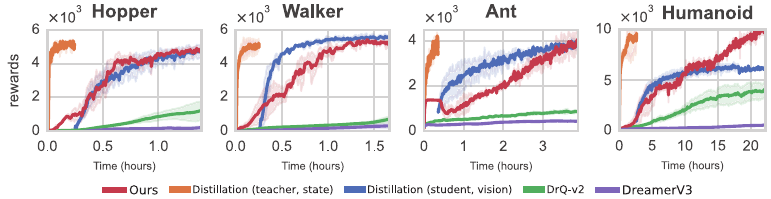
Visual control on classic MuJoCo tasks from third-person RGB.
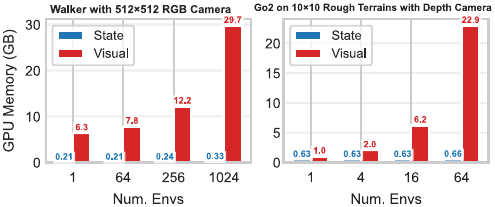
A key bottleneck in applying on-policy methods like PPO to visual RL is memory: they rely on thousands of parallel environments (e.g., 4096) to estimate gradients, and rendering pixel observations for so many environments quickly exhausts GPU memory. By mixing different environments, SDPG estimates gradients accurately with an order of magnitude fewer batch-rendered environments, keeping memory usage on par with off-policy and model-based approaches—and enabling training on a single NVIDIA RTX 4080 GPU.
Memory Usage (GB)
| Method | Hopper | Walker | Ant | Humanoid |
|---|---|---|---|---|
| SDPG (Ours) | 10.2 | 10.3 | 10.3 | 10.5 |
| PPO† | 48 | 48 | 49 | 50 |
| DrQv2 | 10.6 | 8.2 | 10.5 | 11.6 |
| DreamerV3 | 10.8 | 10.8 | 10.8 | 10.9 |
| Distillation | 10.6 | 10.6 | 10.3 | 10.7 |
† PPO memory is estimated with 4096 environments and state-based hyperparameters; all other methods use 64 batched environments.
Egocentric Task Suite
To support further research, we release a suite of realistic, challenging tasks for visual RL spanning dexterous manipulation and challenging locomotion. The suite covers diverse on-robot sensor setups—RGB and depth, single- and multi-camera—paired with proprioception to mimic real hardware, and every policy is trained end-to-end with SDPG.
Sim-to-Real: Unitree Go2
We validate SDPG on Unitree Go2 hardware. The robot uses an egocentric RealSense depth camera to perceive its environment and navigate challenging terrains, including uneven surfaces, boxes, and stairs. The policy is trained entirely in simulation in under 2 hours on a single GPU and transferred to the real world via zero-shot sim-to-real.
BibTeX
@misc{you2026efficientonpolicyvisualrlstochastic,
title={Efficient On-policy Visual-RL via Stochastic Decoupled Policy Gradient},
author={Haoxiang You and Yilang Liu and Davis Zong and Qian Wang and Teeratham Vitchutripop and Qi Wang and Daniel Rakita and Ian Abraham},
year={2026},
eprint={2605.26478},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2605.26478},
}